2. Networked audio systems
This chapter presents a modular networked audio system as a reference for the rest of this white paper. A collection of 12 modules are introduced as building blocks of a system. The described system processes audio in acoustic, analogue and networked formats.
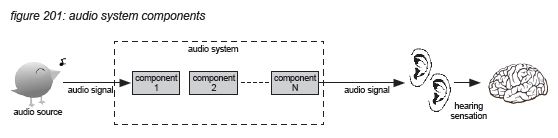
Audio System
A collection of components connected together to process audio signals in order to increase a system’s sound quality.
The following pages will elaborate further on audio processes, formats and components.
2.1 Audio processes
A system’s audio processing can include:
table 201: audio processing types
function
description
conversion
format conversion of audio signals
transport
transport of signals, eg. through cables
storage
storage for editing, transport and playback using audio media, eg. tape, hard disk, CD
mixing
mixing multiple inputs to multiple outputs
change
equalising, compression, amplification etc
The audio system can be mechanical - eg. two empty cans with a tensioned string in-between, or a mechanical gramophone player. But since the invention of the carbon microphone in 1887-1888 individually by Edison and Berliner, most audio systems use electrical circuits. Since the early 1980’s many parts of audio systems gradually became digital, leaving only head amps, A/D and D/A conversion and power amplification remaining as electronic circuits, and microphones and loudspeakers as electroacoustic components. At this moment, digital point-to-point audio protocols such as AES10 (MADI) are being replaced by network protocols such as Dante, EtherSound.
In this white paper, the terms ‘networked audio system’ and ‘digital audio system’ are applied loosely, as many of the concepts presented concern both. When an issue is presented to apply to networked audio systems, the issue does not apply to digital audio systems. When an issue is presented to apply to digital audio systems, it also applies for networked audio systems.
2.2 Audio formats
Although with the introduction of electronic instruments the input can also be an electrical analogue or digitally synthesised signal, in this white paper we will assume all inputs and outputs of an audio system to be acoustic signals. In the field of professional audio, the following identification is used for different formats of audio:
table 202: audio formats
format
description
acoustic
audio signals as pressure waves in air
analogue
audio signals as a non-discrete electrical voltage
digital
audio signals as data (eg. 16 or 24 bit - 44.1, 48, 88.2 or 96kHz)
networked
audio data as streaming or switching packets (eg. Ethernet)
A networked audio system includes these audio formats simultaneously - using specialised components to convert from one to another:
table 203: audio format conversion components
source format
destination format
component
acoustic ->
analogue
microphone
analogue ->
digital/networked
A/D converter
digital/networked ->
analogue
D/A converter
analogue ->
acoustic
loudspeaker
2.3 Audio system components
In this white paper we assume an audio system to be modular, using digital signal processing and networked audio and control distribution. An audio system’s inputs and outputs are assumed to be acoustic audio signals - with the inputs coming from one or multiple acoustic sound sources, and the output or outputs being picked up by one or more listeners. A selection of functional modules constitutes the audio system in between sound sources and listeners.
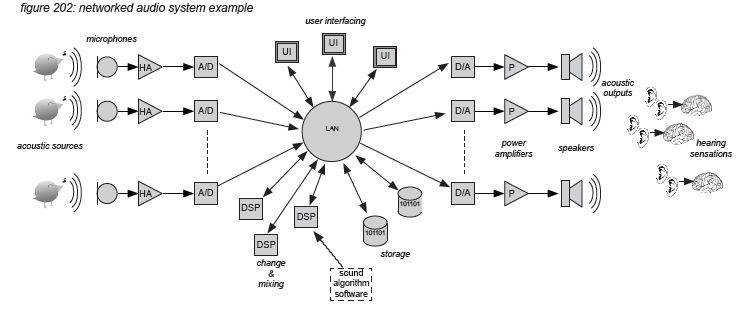
A typical networked audio system is presented in the diagram below. Note that this diagram presents the audio functions as separate functional blocks. Physical audio components can include more than one functional block - eg. a digital mixing console including head amps, A/D and D/A converters, DSP and a user interface. The distribution network in this diagram can be any topology - including ring, star or any combination.